дкXMLФЃЪНжаРЉеЙУЖОйСаБэ
РДдДЃКЛЅСЊЭј 2026-04-15 19:43:32ФЃЪНЩшМЦжаЕФЖЏЬЌЬєеНЃКШчКЮгХбХЕиРЉеЙXMLУЖОйСаБэ дкЯЕЭГМмЙЙЩшМЦРяЃЌвЛИіЦФЮЊГЃМћЕФашЧѓЪЧЃКЯЃЭћЮЊФГИізжЖЮдЄСєРЉеЙПеМфЃЌвдБудкЮДРДФмЬэМгвЛаЉЩшМЦНзЖЮЮДжЊЕФИНМгжЕЁЃЫЕЕУжБАзЕуЃЌОЭЪЧдѕУДДДНЈвЛИіЁАПЩГЄДѓЁБЕФУЖОйжЕСаБэЃПетЬ§Ц№РДМђЕЅЃЌЕЋдквдбЯНїжјГЦЕФXMLФЃЪНЖЈвхжаЃЌЪЕЯжЦ№РДШДУЛФЧУДШнвзЁЃНёЬьЃЌЮвУЧОЭРДЩю
ФЃЪНЩшМЦжаЕФЖЏЬЌЬєеНЃКШчКЮгХбХЕиРЉеЙXMLУЖОйСаБэ
дкЯЕЭГМмЙЙЩшМЦРяЃЌвЛИіЦФЮЊГЃМћЕФашЧѓЪЧЃКЯЃЭћЮЊФГИізжЖЮдЄСєРЉеЙПеМфЃЌвдБудкЮДРДФмЬэМгвЛаЉЩшМЦНзЖЮЮДжЊЕФИНМгжЕЁЃЫЕЕУжБАзЕуЃЌОЭЪЧдѕУДДДНЈвЛИіЁАПЩГЄДѓЁБЕФУЖОйжЕСаБэЃПетЬ§Ц№РДМђЕЅЃЌЕЋдквдбЯНїжјГЦЕФXMLФЃЪНЖЈвхжаЃЌЪЕЯжЦ№РДШДУЛФЧУДШнвзЁЃНёЬьЃЌЮвУЧОЭРДЩюШыСФСФМИжжЦЦНтДЫФбЬтЕФЪЕгУЗНЗЈЁЃ
ЮЪЬтЕФИљдДдкгкЃЌXMLФЃЪНЙцЗЖдкЩшМЦЪБОЭУЛИјЁАУЖОйСаБэРЉеЙЁБСєКѓУХЁЃЙцЗЖАзжНКкзжаДзХЃКУЖОйжЕБиаыдкФЃЪНЖЈвхЪБОЭБЛЭъШЋЁЂЙЬЖЈЕиСаГіРДЁЃетОЭКУБШНЈЗПзгЪБЃЌАбУХПђГпДчЖМКИЫРСЫЃЌвдКѓЯыЛЛИіИќДѓЕФЩГЗЂЖМАсВЛНјШЅЁЃЕЋвЕЮёашЧѓЪЧЛюЕФЃЌаТЙІФмЁЂаТЛяАщЁЂаТЪ§ОнВуГіВЛЧюЁЃКмЖрЭХЖгЖМПЈдкетРяЃКМШЯыв§ШыаТжЕЃЌгжБиаыШЗБЃгыРЯЯЕЭГЕФЮоЗьМцШнЃЌВЛФмЭЦЕЙжиРДЁЃетЦфжаЕФЦНКтвеЪѕЃЌе§ЪЧЮвУЧНёЬьвЊЬНЬжЕФКЫаФЁЃ
ГЄЦкЮШЖЈИќаТЕФдмОЂзЪдДЃК >>>ЕуДЫСЂМДВщПД<<<
ЪВУДЪЧУЖОйСаБэЃПОйИіР§згОЭУїАзСЫЁЃБШШчвЛИіЙњМвДњТыСаБэЃЌзюГѕжЛЖЈвхСЫDEЃЈЕТЙњЃЉЁЂUSЃЈУРЙњЃЉЁЂJPЃЈШеБОЃЉЁЃПЩКѓРДЃЌаТаЫЙњМвЖЋЕлуыЃЈTLЃЉЛђВЈКкЃЈBAЃЉГіЯжСЫЃЌдѕУДАьЃПЫљгавРРЕОЩСаБэЕФЯЕЭГЖМЕУБЛЦШаоИФЃЌетГЩБОЫвВГдВЛЯћЁЃвђДЫЃЌвЛИіРэЯыЕФНтОіЗНАИБиаыЭЌЪБТњзуМИИіПСПЬЬѕМўЃКФмдкЩшМЦКѓЖЏЬЌРЉеЙЁЂФмЭЈЙ§БъзМНтЮіЦїбщжЄЁЂзюКУдквЛИіНтЮіжмЦкФкИуЖЈЃЌВЂЧвзюЙиМќЕФЪЧЁЊЁЊБиаыгыдЪМФЃЪНБЃГжЯђКѓМцШнЁЃ
ЕБШЛЃЌЪаГЁЩЯвВВЛЗІвЛаЉЁАИЩДрЕуЁБЕФЩљвєЁЃгаШЫШЯЮЊЃЌБ№елЬкЪВУДРЉеЙСЫЃЌВЛШчжБНгДДНЈаТЕФЁЂИќПэЫЩЕФЪ§ОнФЃаЭЁЃвВгаШЫЬсвщЃЌБ№гУXMLФЃЪНбщжЄСЫЃЌгУСэвЛЬзЗНАИЃЈШчGenericodeЃЉзіЖўДЮбщжЄЁЃетаЉЗНЗЈИїгаРћБзЃЌЕЋдкКмЖрЧПдМЪјЕФЪЕМЪГЁОАЯТЁЊЁЊБШШчФуБиаыЪЙгУМШЖЈЕФФЃЪНЃЌЧвБиаыдквЛДЮНтЮіжаЭъГЩбщжЄЁЊЁЊЫќУЧОЭгаЕуЁАЫЎЭСВЛЗўЁБСЫЁЃЮвУЧЕФФПБъЃЌЧЁЧЁЪЧдкетаЉЁАСЭюэЁБЯТЃЌЬјГізюгХУРЕФЮшЕИЁЃ
НчЖЈеНГЁЃКРЉеЙУЖОйСаБэЕФЫФДѓЬњТЩ
дкбАевНтОіЗНАИЧАЃЌЮвУЧБиаыУїШЗГЩЙІЕФБъГпЁЃШЮКЮПЩааЕФЗНАИЃЌЖМБиаыТњзувдЯТЫФИігВадЬѕМўЃК
ЕквЛЃЌЩшМЦКѓРЉеЙЃКетЪЧКЫаФЫпЧѓЁЃФЃЪНЖЈИхЁЂЯЕЭГЩЯЯпКѓЃЌБиаыгаФмСІНгФЩаТжЕЃЌЮоТлЪЧЮЊСЫЖдНгаТПЭЛЇЛЙЪЧжЇГжаТвЕЮёЁЃ
ЕкЖўЃЌНтЮіЦїбщжЄЃКаТжЕБиаыФмЭЈЙ§БъзМXMLНтЮіЦїЕФбщжЄЁЃШчЙћбщжЄЛЗНкЭбЙГЃЌЛсМЋДѓдіМгЪЕЯжЕФИДдгЖШКЭГіДэИХТЪЁЃ
ЕкШ§ЃЌЕЅжмЦкЭъГЩЃКНтЮіКЭбщжЄБиаыдкЭЌвЛИіДІРэжмЦкФквЛЦјКЧГЩЁЃв§ШыЖюЭтЕФбщжЄНзЖЮЛђЙЄОпЃЌдкзЗЧѓадФмКЭМђНрадЕФГЁОАЯТЭљЭљЪЧВЛПЩНгЪмЕФЁЃ
ЕкЫФЃЌЯђКѓМцШнЃКетЪЧЕзЯпЁЃШЮКЮИФЖЏЖМВЛФмЦЦЛЕвбгаЯЕЭГЖдОЩФЃЪНЕФРэНтКЭДІРэЃЌЗёдђОЭЪЇШЅСЫЁАРЉеЙЁБЕФвтвхЃЌГЩСЫЁАЧЈвЦЁБЁЃ
НгЯТРДЃЌЮвУЧвдвЛИіОпЬхЕФАИР§РДНтЦЪетаЉЗНАИЁЃМйЩшгавЛИіЙуЗКЪЙгУЕФЁАЛщвізДПіЁБУЖОйСаБэЃЌЫќАќКЌСЫжюШчЁАвбЛщЁБЁЂЁАРывьЁБЁЂЁАЮДЛщЁБЕШБъзМжЕЃЈШчЧхЕЅ1ЫљЪОЃЉЁЃЯждкЃЌФуЕФЙЋЫОашвЊгывЛИіживЊЕФаТЛяАщЖдНгЃЌЖдЗНЪЙгУСЫвЛИіаТЕФзДЬЌжЕЃКЁАУёЪТНсКЯЁБЁЃДггявхЩЯПДЃЌетЭъШЋЪєгкЁАЛщвізДПіЁБЗЖГыЃЌЕЋФуЕФЯжгаФЃЪНРяУЛгаЫќЁЃдѕУДАьЃП
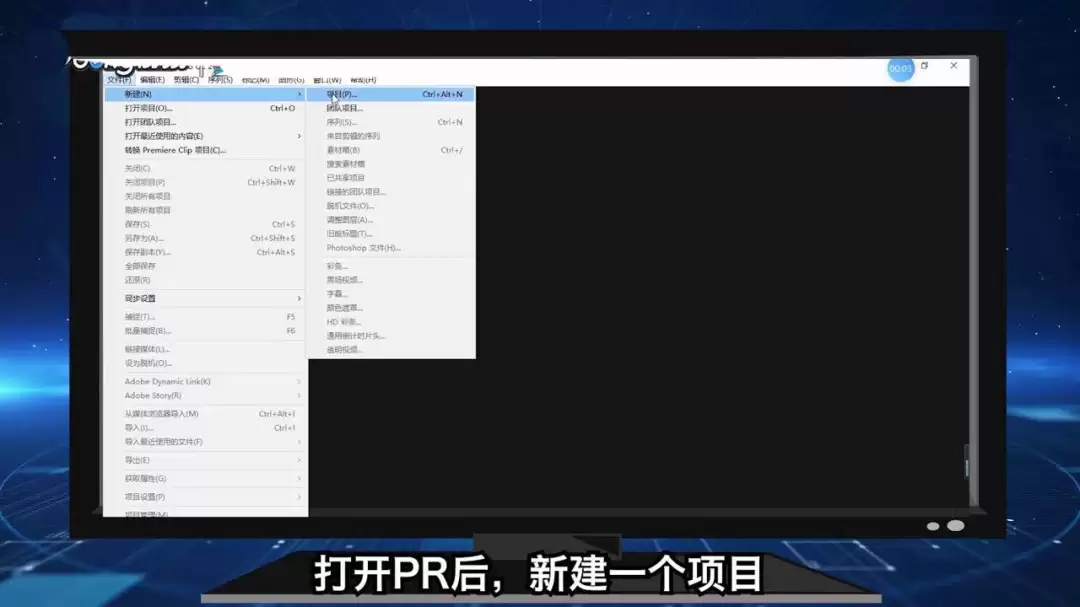
ЗНАИвЛЃКжБНгБрМдЪМФЃЪН
зюжБЙлЕФАьЗЈЃЌФЊЙ§гкжБНгДђПЊдЪМЕФФЃЪНЮФМўЃЌАбЁАУёЪТНсКЯЁБетИіаТУЖОйжЕМгНјШЅЁЃ
гХЕуЯдЖјвзМћЃКМђЕЅЁЂжБНгЃЌЫљгабщжЄТпМЖМФмЮоЗьЙЄзїЁЃ
ЕЋШБЕуИќжТУќЃКЪзЯШЃЌФуЁАДлИФЁБСЫдЪМФЃЪНЁЃШчЙћетИіФЃЪНЪЧгЩаавЕаЛсЛђКЫаФЛяАщЮЌЛЄВЂЖЈЦкИќаТЕФЃЌУПДЮЙйЗНЗЂВМаТАцБОЃЌФуЖМЕУЪжЖЏАбзджЦЕФЁАВЙЖЁЁБжиаТДђвЛБщЃЌЮЌЛЄГЩБОИпЃЌЧвШнвзГіДэЁЃЦфДЮЃЌетвЊЧѓФугЕгаВЂгаШЈаоИФдЪМФЃЪНЮФМўЃЌетдкКмЖрБъзМЛЏазїГЁОАжаЪЧВЛЯжЪЕЕФЁЃ
ЗНАИЖўЃКДДНЈаТСаБэЃЌгыдСаБэКЯВЂ
МШШЛВЛФмИФБ№ШЫЕФЃЌФЧОЭздМКдьвЛИіЁЃЮвУЧПЩвдЮЊРЉеЙжЕЕЅЖРДДНЈвЛИіаТЕФУЖОйРраЭЃЈШчЧхЕЅ2ЃЌжЛАќКЌЁАCivilUnionЁБЃЉЃЌШЛКѓРћгУXML SchemaЕФ
етИіЗНЗЈЕФНјВНжЎДІдкгкЃЌЫќБЃГжСЫдЪМУЖОйСаБэЕФДПНрадЃЌУЛгаЖдЦфНјааЫПКСИФЖЏЁЃ
ЕЋЬєеНвРШЛДцдкЃКЪзЯШЃЌЫќБОжЪЩЯвРШЛвЊЧѓЫљгажЕдкЩшМЦЪБЪЧвбжЊЕФЃЌжЛВЛЙ§ЗждкСЫСНИіСаБэРяЃЌВЂЗЧеце§ЕФЁАКѓЦкАѓЖЈЁБЁЃЦфДЮЃЌЫќвРРЕгк
ЗНАИШ§ЃКФЃЪН+е§дђБэДяЪНЃЌдЄСєРЉеЙЭЈЕР
етЪЧвЛИіИќЧЩУюЕФЫМТЗЃЌЮвУЧв§ШывЛЕуЁАФЃЪНЦЅХфЁБРДДђЦЦНЉОжЁЃвдЁАИіШЫблОІбеЩЋЁБУЖОйСаБэЮЊР§ЃЈШчЧхЕЅ4ЃЉЃЌБъзМжЕгаКкЩЋЁЂРЖЩЋЁЂТЬЩЋЕШЁЃЮвУЧЯыдЪаэЮДРДЬэМгШчЁАРЖТЬЩЋЁБетбљЕФЗЧБъзМжЕЁЃ
ОпЬхзіЗЈЪЧЃКЮвУЧВЛНіЖЈвхвЛИіУЖОйСаБэЃЌЛЙЭЌЪБЖЈвхвЛИіе§дђБэДяЪНФЃЪНЃЈШчЧхЕЅ5ЃЉЁЃетИіФЃЪНЙцЖЈЃЌЫљгавдЁАx:ЁБЮЊЧАзКЕФзжЗћДЎЃЌЖМБЛЪгзїгааЇЕФРЉеЙжЕЁЃШЛКѓЃЌдйДЮЪЙгУ
етбљвЛРДЃЌдкXMLЪЕР§жаЃЈШчЧхЕЅ7ЃЉЃЌФуОЭПЩвдМШЪЙгУЁАBlackЁБетбљЕФБъзМжЕЃЌвВПЩвдЪЙгУЁАx:TealЁБетбљЕФРЉеЙжЕЃЌЫќУЧЖМФмЭЈЙ§ЭЌвЛНтЮіЦїЕФвЛДЮадбщжЄЁЃ
етИіЗНАИЕФССЕудкгкЫќЪЕЯжСЫеце§ЕФЩшМЦКѓРЉеЙЃЈШЮКЮЗћКЯЧАзКЙцдђЕФжЕЮДРДЖМПЩНгЪмЃЉЃЌВЂЧвЧхЮњЕиЧјЗжСЫБъзМжЕгыРЉеЙжЕЁЃ
ашвЊзЂвтЕФЪЧЃЌЯТгЮгІгУашвЊНтЮідЊЫиФкШнЃЌЭЈЙ§ЧАзКЁАx:ЁБРДХаЖЯетЪЧвЛИіРЉеЙжЕЁЃЭЌЪБЃЌЫќвРШЛвРРЕНтЮіЦїЖде§дђБэДяЪНКЭ
ЗНАИЫФЃКЗжЖјжЮжЎЃЌЩшСЂзЈЪєРЉеЙзжЖЮ
ЕБЮвУЧЮоЗЈЛђВЛЯыИФЖЏдгазжЖЮЕФШЮКЮЖЈвхЪБЃЌПЩвдЛЛИіЫМТЗЃКВЛРЉеЙдгаУЖОйзжЖЮБОЩэЃЌЖјЪЧЮЊРЉеЙФкШнЕЅЖРПЊБйвЛИіЁАаТзжЖЮЁБЁЃ
Р§ШчЃЌвЛИіЁАвРРЕЙиЯЕЁБУЖОйСаБэЃЈШчЧхЕЅ8ЃЉАќКЌСЫЁАХфХМЁБЁЂЁАзгХЎЁБЕШЙЬЖЈЙиЯЕЁЃЕБГіЯжвЛжжаТЕФЁЂЮДБЛЖЈвхЕФЙиЯЕЪБЃЌЮвУЧВЛЭљдРДЕФУЖОйзжЖЮРягВШћаТжЕЃЌЖјЪЧдкЪ§ОнФЃаЭжадіМгвЛИіЁАРЉеЙЙиЯЕЫЕУїЁБзжЖЮЁЃБъзМЙиЯЕШдгУдзжЖЮБэЪОЃЌЬиЪтЙиЯЕдђБъМЧЮЊЁАЦфЫћЁБЃЌВЂНЋЦфОпЬхУшЪіЬюШыаТЕФРЉеЙзжЖЮЁЃ
етбљзізюДѓЕФКУДІЪЧЪЕЯжСЫГЙЕзЕФНтёюЁЃдЪМУЖОйзжЖЮБЃГжОјЖдЮШЖЈЃЌЭъШЋМцШнОЩЯЕЭГЁЃЫљгаРЉеЙадИДдгЖШЖМБЛИєРыЕНаТЕФЁЂзЈЮЊРЉеЙЩшМЦЕФзжЖЮжаЁЃ
ЕБШЛЃЌДњМлвВЪЧУїЯдЕФЃКЪ§ОнНсЙЙКЭДІРэТпМЛсБфЕУЩдИДдгЃЌвђЮЊгІгУашвЊЭЌЪБДІРэСНИізжЖЮВХФмЕУЕНЭъећаХЯЂЁЃетИќЯёЪЧвЛжжМмЙЙВуУцЕФЩшМЦОіВпЃЌЖјЗЧЕЅДПЕФгяЗЈММЧЩЁЃ
ЫЕЕНЕзЃЌУЛгавЛжжЗНАИЪЧЭъУРЕФвјЕЏЁЃбЁдёФФвЛжжЃЌШЁОігкФуЕФОпЬхеНГЁЃКФуЖддЪМФЃЪНЕФПижЦСІЁЂЖдЙЄОпСДЕФвРРЕЁЂЖдЪ§ОнДПНрадЕФвЊЧѓЃЌвдМАЖдЮДРДРЉеЙЦЕЖШЕФдЄХаЁЃРэНтУПвЛжжЗНЗЈЕФФкдкТпМгыШЈКтЃЌВХФмдкЩшМЦжЎГѕЃЌОЭЮЊБфЛЏдЄСєКУгХбХЕФШыПкЁЃ
ЯРгЮЯЗЗЂВМДЫЮФНіЮЊСЫДЋЕнаХЯЂЃЌВЛДњБэЯРгЮЯЗЭјеОШЯЭЌЦфЙлЕуЛђжЄЪЕЦфУшЪі
ЯрЙиЙЅТд
ИќЖрЭЌРрИќаТ
ИќЖр




ШШгЮЭЦМі
ИќЖр-

- КНЬьЛ№М§ФЃФтЦї
- Android/ | ФЃФтбјГЩ
- 2026-04-07
-

- УќдЫЦяЪПЭХ
- Android/ | НЧЩЋАчбн
- 2026-03-30
-

-

-

-

-

- зЙаЧДѓТН ТђЖЯАц
- Android/ | НЧЩЋАчбн
- 2026-03-30
-







- ЯцICPБИ14008430КХ-1 ЯцЙЋЭјАВБИ 43070302000280КХ
- All Rights Reserved
- БОеОЮЊЗЧгЏРћЭјеОЃЌВЛНгЪмШЮКЮЙуИцЁЃБОеОЫљгаШэМўЃЌЖМгЩЭјгб
- ЩЯДЋЃЌШчгаЧжЗИФуЕФАцШЈЃЌЧыЗЂгЪМўИјxiayx666@163.com
- ЕжжЦВЛСМЩЋЧщЁЂЗДЖЏЁЂБЉСІгЮЯЗЁЃзЂвтздЮвБЃЛЄЃЌНїЗРЪмЦЩЯЕБЁЃ
- ЪЪЖШгЮЯЗвцФдЃЌГСУдгЮЯЗЩЫЩэЁЃКЯРэАВХХЪБМфЃЌЯэЪмНЁПЕЩњЛюЁЃ