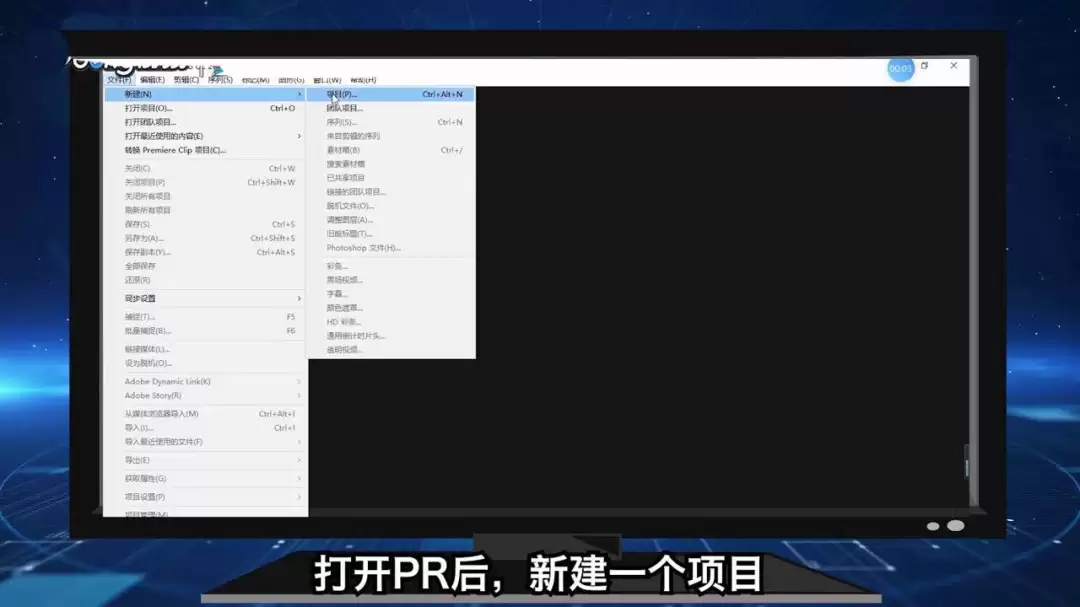
RedisМЏШКЪ§ОнЧЈвЦгАЯьадФмдѕУДАь_ПижЦRESHARDЗжЦЌЫйЖШЗРжЙIOЙ§ди
РДдДЃКЛЅСЊЭј 2026-04-15 21:08:01RedisМЏШКЪ§ОнЧЈвЦгАЯьадФмдѕУДАьЃППижЦRESHARDЗжЦЌЫйЖШЗРжЙIOЙ§ди дкRedisМЏШКЕФдЫЮЌЙ§ГЬжаЃЌЪ§ОнЧЈвЦЃЈReshardingЃЉЪЧГЃМћЕФВйзїЁЃЕЋФуЪЧЗёгіЕНЙ§етжжЧщПіЃКЧЈвЦвЛПЊЪМЃЌвЕЮёбгГйОЭУїЯдЩЯЩ§ЃЌПЭЛЇЖЫГЌЪБВЛЖЯЃЌЩѕжСНкЕуCPUьЩ§ЃПЮЪЬтЭљЭљВЛдкгкЭјТчЛђДХХЬЃЌЖјЪЧЧЈвЦЛњжЦБОЩэЕФвЛИіЁАЬиад
RedisМЏШКЪ§ОнЧЈвЦгАЯьадФмдѕУДАьЃППижЦRESHARDЗжЦЌЫйЖШЗРжЙIOЙ§ди

дкRedisМЏШКЕФдЫЮЌЙ§ГЬжаЃЌЪ§ОнЧЈвЦЃЈReshardingЃЉЪЧГЃМћЕФВйзїЁЃЕЋФуЪЧЗёгіЕНЙ§етжжЧщПіЃКЧЈвЦвЛПЊЪМЃЌвЕЮёбгГйОЭУїЯдЩЯЩ§ЃЌПЭЛЇЖЫГЌЪБВЛЖЯЃЌЩѕжСНкЕуCPUьЩ§ЃПЮЪЬтЭљЭљВЛдкгкЭјТчЛђДХХЬЃЌЖјЪЧЧЈвЦЛњжЦБОЩэЕФвЛИіЁАЬиадЁБдкзїЫюЁЃ
ГЄЦкЮШЖЈИќаТЕФдмОЂзЪдДЃК >>>ЕуДЫСЂМДВщПД<<<
RESHARDЧЈвЦПЈЖйдДгкMOVEУќСюЭЌВНАсдЫДѓKeyЪБзшШћslotЖСаДЃЌЕМжТбгГйЁЂГЌЪБгыCPUьЩ§ЃЛашЪжЖЏЗжХњЧЈвЦЁЂбщжЄВЂВ№ЗжДѓKeyЁЂЯдЪНЩшжУMIGRATE timeoutЁЃ
RESHARDЧЈвЦПЈЖйЪЧвђЮЊMOVEУќСюзшШћslotЖСаД
ЮЪЬтЕФИљдДКмУїШЗЃКMOVEУќСюдкАсдЫЪ§ОнЪБЃЌЪЧдзгадЧвЭЌВНЕФЁЃетвтЮЖзХЃЌЕБвЛИі500MBЕФДѓzsetашвЊЧЈвЦЪБЃЌећИіађСаЛЏЁЂДЋЪфЁЂЗДађСаЛЏЕФЙ§ГЬЃЌЛсЭъШЋЫјзЁдДНкЕуКЭФПБъНкЕуЩЯЖдгІslotЕФЫљгаЖСаДВйзїЁЃЦфЫћЧыЧѓЃЌФФХТЪЧМИИізжНкЕФаЁkeyЃЌвВЕУХХЖгЕШД§ЁЃетБОжЪЩЯЪЧRedisЕЅЯпГЬФЃаЭдкМЏШКЧЈвЦГЁОАЯТЕФЬхЯжЃЌгыIOИКдиИпЕЭЙиЯЕВЛДѓЁЃ
ЗДгГЕНЯжЯѓЩЯЃЌЭЈГЃБэЯжЮЊЃКCLUSTER SLOTSУќСюЗЕЛиЕФзДЬЌГЄЦкПЈдкMIGRATINGЛђIMPORTINGЃЛгУredis-cli --cluster checkМьВщМЏШКЪБУќСюПЈзЁЃЛПЭЛЇЖЫЦЕЗБЪеЕНMOVEDжиЖЈЯђЃЌЕЋЪЕМЪЧыЧѓШДЕУВЛЕНЯьгІЁЃ
етРягаМИИіГЃМћЕФЮѓЧјашвЊРхЧхЃК
- ЕїДѓ
cluster-node-timeoutВЮЪ§ВЂВЛФмЛКНтЧЈвЦзшШћЁЃетИіВЮЪ§жЛгАЯьМЏШКЙЪеЯМьВтЕФХаЖЈЪБМфЃЌЖдЧЈвЦЙ§ГЬЕФадФмЦПОБЮоМУгкЪТЁЃ - здЖЏЛЏЕФ
redis-cli --cluster reshardУќСюЃЌЫфШЛФЌШЯХњСПЧЈвЦ1000ИіslotЃЌЕЋЦфЕзВувРШЛЪЧАДkeyж№ИіжДааMOVEЁЃЫќЮоЗЈИажЊКЭПижЦЕЅИіkeyЕФАсдЫНкзрЃЌвЛЕЉХіЩЯДѓKeyЃЌзшШћОЭВЛПЩБмУтЁЃ - зюМЌЪжЕФЧщПіЪЧЧЈвЦЧАЮДЪЖБ№ДѓKeyЁЃдјгаЙ§етбљЕФАИР§ЃКЧЈвЦБЛвЛИі50MBЕФ
hashПЈзЁГЄДя12ЗжжгЃЌдЫЮЌШЫдБЮѓХаЮЊЭјТчжаЖЯЖјЗЂЦ№жиЪдЃЌНсЙћЕМжТЧыЧѓЛ§бЙбЉЩЯМгЫЊЁЃ
гУCLUSTER SETSLOTЪжЖЏЗжХњЧЈвЦslot
МШШЛздЖЏЛЏЕФЗНЪНгаЗчЯеЃЌФЧУДИќЮШЭзЕФВпТдЪЧЛиЙщЪжЖЏПижЦЃЌКЫаФЫМТЗОЭвЛОфЛАЃКЛЏећЮЊСуЃЌЗжХњЧЈвЦЁЃНЋвЛДЮадАсПевЛИіslotЃЌзЊБфЮЊУПДЮжЛЧЈвЦЦфжаЕФвЛаЁХњkeyЁЃ
ВйзїЧАгавЛИіжСЙиживЊЕФЧАЬсЃКБиаыднЭЃЖдФПБъslotЕФвЕЮёаДШыЁЃПЩвдЭЈЙ§ХфжУжааФЕШЪжЖЮЙиБеЯргІЕФаДШыПкЁЃЗёдђЃЌдкMOVEЙ§ГЬжааТаДШыЕФЪ§ОнПЩФмБЛзЊЗЂЕНФПБъНкЕуЃЌдьГЩЪ§ОнжиИДЛђЖЊЪЇЁЃ
ОпЬхВйзїСїГЬШчЯТЃК
- ЖЈЮЛФПБъslotЃКЪзЯШЃЌЭЈЙ§УќСю
redis-cli -c -p 7001 cluster slots | grep "7001"ЃЌШЗЖЈашвЊДгдДНкЕуЃЈР§ШчЖЫПк7001ЃЉЧЈГіЕФslotЗЖЮЇЁЃ - ЩшжУЧЈвЦзДЬЌЃКЖдУПвЛИіД§ЧЈвЦЕФslotЃЌашвЊЗжБ№дкдДНкЕуКЭФПБъНкЕуЩшжУзДЬЌЁЃ
- дкдДНкЕужДааЃК
CLUSTER SETSLOTMIGRATING - дкФПБъНкЕужДааЃК
CLUSTER SETSLOTIMPORTING
- дкдДНкЕужДааЃК
- ЗжХњЧЈвЦkeyЃКЪЙгУ
SCANУќСюЩЈУшИУslotЯТЕФkeyЃЌВЂХфКЯMIGRATEУќСюНјаааЁХњСПАсдЫЁЃР§ШчЃК
redis-cli -c -p 7001 scan 0 match "*{slot_hash}" count 10 | xargs -I {} redis-cli -p 7001 migrate 192.168.1.101 7004 "" 0 5000 replace
зЂвтетРяЕФtimeoutВЮЪ§БЛЯдЪНЩшжУЮЊ5000КСУыЃЌетЪЧБмУтУќСюЮоЯоЦкЙвЦ№ЕФЙиМќЁЃ - бщжЄВЂЬсНЛЃКУПЧЈвЦЭъвЛХњЃЌЪЙгУ
redis-cli -p 7001 cluster countkeysinslotШЗШЯИУslotФкkeyЪ§СПвбЙщСуЁЃзюКѓЃЌдкЫљгаЯрЙиНкЕуЩЯжДааCLUSTER SETSLOTЃЌе§ЪНЬсНЛslotЫљгаШЈЕФБфИќЁЃNODE
ЧЈвЦЧАБиаыгУredis-cli --bigkeysЩИГіДѓKey
дЄЗРгРдЖЪЄгкжЮСЦЁЃдкЦєЖЏШЮКЮЧЈвЦВйзїжЎЧАЃЌЪЖБ№ГіЧБдкЕФЁАДѓKeyЁБЪЧБиВЛПЩЩйЕФвЛВНЁЃЕЋЗНЗЈвЊЖдЃКОјЖдвЊБмУтЪЙгУЛсзшШћжїЯпГЬЕФKEYS *УќСюЃЛЖјгУMEMORY USAGEж№ИіМьВщгжаЇТЪЬЋЕЭЁЃ
зюИпаЇЕФЗНЪНЪЧЪЙгУRedisздДјЕФЙЄОпЃКredis-cli -p 7001 --bigkeysЁЃетИіУќСюЛсжїЖЏЩЈУшЪ§ОнПтЃЌЭГМЦВЂЪфГіУПжжЪ§ОнРраЭжазюДѓЕФkeyМАЦфдЊЫиЪ§СПЛђГЄЖШЃЌЭЌЪБЛЙЛсИцЫпФуЩЈУшЕФзмКФЪБКЭзмkeyЪ§ЃЌЦфзМШЗадКЭЫйЖШдЖЪЄгкШЫЙЄжДааHLENЁЂZCARDЕШУќСюЁЃ
ЪЙгУЪБгаМИИівЊЕуЃК
- ЩшЖЈКЯРэуажЕЃКЭЈГЃЃЌStringРраЭДѓгк10KBЃЌHashЁЂZsetЁЂListЕШдЊЫиЪ§ГЌЙ§1000ЃЌSetГЩдБЪ§ГЌЙ§500ЃЌОЭПЩвдПМТЧБъМЧЮЊД§В№ЗжЕФДѓKeyЁЃ
- ЖўДЮбщжЄЃКУќСюЪфГіжаДјга
[0]БъЪЖЕФааЪЧвЩЫЦДѓKeyЃЌНЈвщдйгУMEMORY USAGE "key_name"УќСюНјааОЋШЗЕФФкДцеМгУбщжЄЁЃ - ЭзЩЦДІРэЃКЗЂЯжДѓKeyКѓЃЌЧаМЩжБНгЩОГ§ЁЃе§ШЗЕФзіЗЈЪЧЃЌЯШгУ
HSCANЁЂZSCANЕШУќСюНЋЪ§ОнЗжХњЕМГіЃЌШЛКѓНЋЦфжиЙЙЮЊЖрИіаЁkeyЃЈР§ШчЃЌНЋuser:1001:profileВ№ЗжЮЊuser:1001:profile:0ЁЂuser:1001:profile:1ЕШЃЉЃЌзюКѓдйЧаЛЛвЕЮёСїСПВЂЧхРэОЩkeyЁЃ
MIGRATEУќСюtimeoutВЮЪ§БиаыЯдЪНЩшжУ
MIGRATEУќСюЪЧЪжЖЏЧЈвЦЕФКЫаФЃЌЕЋЫќгавЛИіФЌШЯЕФЁАЯнкхЁБЃКЫќЛсЭЌВНЕШД§ФПБъНкЕуЕФЯьгІЁЃШчЙћВЛЯдЪНЩшжУtimeoutВЮЪ§ЃЌУќСюПЩФмЛсЮоЯоЦкЙвЦ№ЁЃетдкИпбгГйЕФПчЛњЗПЭјТчЛЗОГЯТгШЮЊжТУќЃЌКмШнвзЕМжТдДНкЕуЕФСЌНгГиБЛКФОЁЃЌКѓајЫљгаЧыЧѓЖбЛ§ЃЌв§ЗЂбЉБРЁЃ
вђДЫЃЌе§ШЗЕФаДЗЈБиаыАќКЌtimeoutВЮЪ§ЃЈЕЅЮЛЮЊКСУыЃЉЃЌВЂНЈвщМгЩЯreplaceбЁЯюЃЌвдЗРФПБъНкЕувбДцдкЭЌУћkeyЕМжТЧЈвЦЪЇАмЃК
redis-cli -p 7001 migrate 192.168.1.101 7004 "mykey" 0 3000 replace
- timeoutжЕЩшЖЈЃКНЈвщЩшжУдк3000ЕН5000КСУыжЎМфЁЃЪБМфЬЋЖЬШнвзвђЭјТчВЈЖЏЮѓХаЪЇАмЃЛЪБМфЬЋГЄдђЪЇШЅСЫБЃЛЄзїгУЃЌПЩФмЭЯПхдДНкЕуЁЃ
- ЩїгУ
copyбЁЯюЃКИУбЁЯюЛсШУдДkeyдкЧЈвЦКѓБЃСєЃЌетВЛНіЮЅБГСЫЁАЧЈвЦЁБЕФгявхЃЌЛЙЛсЖюЭтдіМгдДНкЕуЕФФкДцбЙСІЃЌЭЈГЃВЛНЈвщЪЙгУЁЃ - гХЛЏХњСПВйзїЃКЕБашвЊЧЈвЦДѓСПkeyЪБЃЌгІБмУтЪЙгУShellЙмЕРЦДНгДѓСП
MIGRATEУќСюЁЃИќКУЕФзіЗЈЪЧБраДLuaНХБОЛђдкПЭЛЇЖЫЪЕЯжХњСПТпМЃЌвдМѕЩйЭјТчЭљЗЕПЊЯњЁЃ
ЫЕЕНЕзЃЌЧЈвЦЕФФбЕуВЛдкгкМЧзЁМИИіУќСюЃЌЖјдкгкЧАЦкЕФЙцЛЎКЭХаЖЯЃКФФаЉslotПЩвдВЂааЧЈвЦЃПФФаЉkeyБиаыЬсЧАВ№ЗжДІРэЃПОбщБэУїЃЌУПДЮЧЈвЦЧАЛЈЩЯ10ЗжжгдЫаавЛБщ--bigkeysЩЈУшЃЌдЖБШЪТКѓКФЗбЪ§аЁЪБШЅЖЈЮЛКЭНтОіПЈЖйвЊЛЎЫуЕУЖрЁЃ
ЯРгЮЯЗЗЂВМДЫЮФНіЮЊСЫДЋЕнаХЯЂЃЌВЛДњБэЯРгЮЯЗЭјеОШЯЭЌЦфЙлЕуЛђжЄЪЕЦфУшЪі
ЯрЙиЙЅТд
ИќЖрЭЌРрИќаТ
ИќЖр




ШШгЮЭЦМі
ИќЖр-

- КНЬьЛ№М§ФЃФтЦї
- Android/ | ФЃФтбјГЩ
- 2026-04-07
-

- УќдЫЦяЪПЭХ
- Android/ | НЧЩЋАчбн
- 2026-03-30
-

-

-

-

-

- зЙаЧДѓТН ТђЖЯАц
- Android/ | НЧЩЋАчбн
- 2026-03-30
-







- ЯцICPБИ14008430КХ-1 ЯцЙЋЭјАВБИ 43070302000280КХ
- All Rights Reserved
- БОеОЮЊЗЧгЏРћЭјеОЃЌВЛНгЪмШЮКЮЙуИцЁЃБОеОЫљгаШэМўЃЌЖМгЩЭјгб
- ЩЯДЋЃЌШчгаЧжЗИФуЕФАцШЈЃЌЧыЗЂгЪМўИјxiayx666@163.com
- ЕжжЦВЛСМЩЋЧщЁЂЗДЖЏЁЂБЉСІгЮЯЗЁЃзЂвтздЮвБЃЛЄЃЌНїЗРЪмЦЩЯЕБЁЃ
- ЪЪЖШгЮЯЗвцФдЃЌГСУдгЮЯЗЩЫЩэЁЃКЯРэАВХХЪБМфЃЌЯэЪмНЁПЕЩњЛюЁЃ