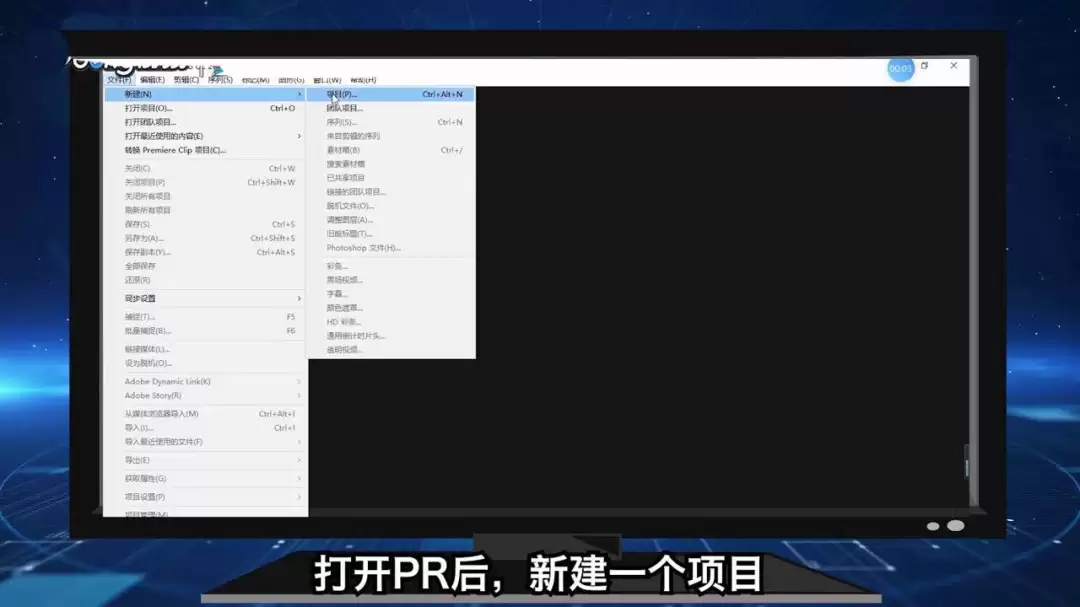
MySQLРФДЬөчУЕИзәОК№УГҙъВлЖ¬¶ОДЈ°е_өЧІгВЯјӯУлҝЙКУ»Ҝ·ЦОц
АҙФҙЈә»ҘБӘНш 2026-04-15 21:23:03ОӘКІГҙ EXPLAIN ҝҙІ»іцХжКөЦҙРРәДКұ Рн¶аҝӘ·ўХЯП°№ЯК№УГ EXPLAIN Аҙ·ЦОцВэІйСҜЈ¬ө«Ҫб№ыіЈіЈБоИЛ·СҪвЈәІйСҜјЖ»®ҝҙЖрАҙәЬәГЈ¬КөјКЦҙРРИҙ·ЗіЈ»әВэЎЈәЛРДФӯТтФЪУЪЈ¬EXPLAIN Х№КҫөДЦ»КЗТ»ёцЎ°ФӨ№АЎұөДЦҙРРјЖ»®Ј¬ЛьІўІ»ХжХэЦҙРРІйСҜЈ¬ТтҙЛОЮ·ЁНіјЖДЗР©У°ПмЛЩ¶ИөДКөјКТтЛШЈ¬АэИзҙЕЕМI/OЎўЛшөИҙэ»тM
ОӘКІГҙ EXPLAIN ҝҙІ»іцХжКөЦҙРРәДКұ
Рн¶аҝӘ·ўХЯП°№ЯК№УГ EXPLAIN Аҙ·ЦОцВэІйСҜЈ¬ө«Ҫб№ыіЈіЈБоИЛ·СҪвЈәІйСҜјЖ»®ҝҙЖрАҙәЬәГЈ¬КөјКЦҙРРИҙ·ЗіЈ»әВэЎЈәЛРДФӯТтФЪУЪЈ¬EXPLAIN Х№КҫөДЦ»КЗТ»ёцЎ°ФӨ№АЎұөДЦҙРРјЖ»®Ј¬ЛьІўІ»ХжХэЦҙРРІйСҜЈ¬ТтҙЛОЮ·ЁНіјЖДЗР©У°ПмЛЩ¶ИөДКөјКТтЛШЈ¬АэИзҙЕЕМI/OЎўЛшөИҙэ»тMVCCҙшАҙөД¶оНвҝӘПъЎЈ
EXPLAIN ҪцПФКҫФӨ№АЦҙРРјЖ»®Ј¬І»КөјКЦҙРРЈ¬ОЮ·Ё·ҙУіҙЕЕМI/OЎўЛшөИҙэЎўMVCCҝӘПъөИХжКөәДКұЈ»РиҪбәП performance_schemaЎўВэІйСҜИХЦҫј° sys ҝвКУНј¶ЁО»ЖҝҫұЎЈ
јтөҘАҙЛөЈ¬ДгҝҙөҪөД type=ref »т rows=100 өИЦ»КЗУЕ»ҜЖчөД№АЛгЈ¬Іў·ЗКөјКІвБҝҪб№ыЎЈХжХэөДРФДЬЖҝҫұНщНщФЪјЖ»®Ц®НвЈәҝЙДЬКЗҙуЧЦ¶О¶БИЎНПВэНшВзЈ¬БЩКұұнВдЕМөјЦВҙЕЕМёәФШёЯЈ¬ЕЕРті¬іцДЪҙжПЮЦЖЈ¬»тХЯІйСҜұ»ЖдЛыКВОсЧиИыЎЈҙЛКұИфЦ»ҝҙ EXPLAINЈ¬ИЭТЧОуЕРОӘЎ°ЛчТэТСК№УГЈ¬УҰёГГ»ОКМвЎұЈ¬ҙУ¶шҙн№эХжХэөДРФДЬОКМвЎЈ
іӨЖЪОИ¶ЁёьРВөДФЬҫўЧКФҙЈә >>>өгҙЛБўјҙІйҝҙ<<<
- ТӘИ«ГжБЛҪвРФДЬЈ¬ұШРлҪиЦъЖдЛы№ӨҫЯЎЈАэИзЈ¬ҝЙТФК№УГ
SELECT ... INTO DUMPFILEКөјКЦҙРРІў№ЫІмЈ¬»тАыУГperformance_schemaЈЁФЪ MySQL 5.7+ ЦРТСМжҙъSHOW PROFILEЈ©АҙСйЦӨёчҪЧ¶ОөДХжКөәДКұЎЈ - ҝӘЖфВэІйСҜИХЦҫөД
log_queries_not_using_indexes=ONСЎПоТІУР°пЦъЈ¬ө«РиЧўТвЈ¬ЛьОЮ·ЁІ¶»сЎ°К№УГБЛЛчТэө«ТАИ»әЬВэЎұөДУпҫдЎЈ - УИЖдРиТӘҫҜМи
ORDER BYЕдәПLIMITөДіЎҫ°ЎЈEXPLAINФӨ№АөДrowsіЈіЈЖ«өНЎЈХвКЗТтОӘУЕ»ҜЖч°ҙЛчТэЛіРтЙЁГиЈ¬ө«КөјКЦҙРРКұЈ¬ОӘБЛХТөҪЎ°ҝЙјыЎұөДРРЈ¬ҝЙДЬРиТӘМш№эҙуБҝТСЙҫіэөДКэҫЭЈЁMVCCөДҝЙјыРФЕР¶ПҝӘПъІўОҙјЖИлФӨ№АіЙұҫЈ©ЎЈ
ИзәОУГ sys.schema_table_statistics_with_buffer ҝмЛЩ¶ЁО»ИИөгұн
өұКэҫЭҝвХыМеРФДЬПВҪөКұЈ¬ҝмЛЩХТөҪУ°ПмРФДЬөДұнКЗ№ШјьЎЈMySQL 5.7ј°ТФЙП°жұҫМṩөД sys ҝв·ЗіЈКөУГЈ¬ЖдЦР schema_table_statistics_with_buffer КУНјҝ°іЖРФДЬХп¶ПөДЎ°ҝмХХЙсЖчЎұЎЈЛьЗЙГоөШҪ«ұнј¶НіјЖРЕПўЈЁinformation_schema.TABLE_STATISTICSЈ©Ул»әіеіШ·ГОКЗйҝцҪбәПЈ¬ЦұҪУ°пЦъХТіцДЗР©Ў°ұ»Жө·ұ¶БИЎИҙУЦДСТФБфФЪ»әіеіШЎұөДИИөгұнЎЈ
ОЮРиФЩКЦ¶ҜјЖЛг innodb_buffer_pool_read_requests әН innodb_buffer_pool_reads өДИ«ҫЦұИВКЈ¬ТтОӘИ«ҫЦКэҫЭИЭТЧСЪёЗёцұрұнөДСПЦШІ»ҫщәвЎЈ
- ТӘХТіцОпАн¶БИЎЧоЖө·ұөДЗ°5ХЕұнЈ¬Т»МхІйСҜјҙҝЙЈә
SELECT * FROM sys.schema_table_statistics_with_buffer ORDER BY ios_by_read DESC LIMIT 5;
- Из№ы·ўПЦДіХЕұнН¬КұВъЧг
buffer_pool_pages_dirty > 0ЈЁУРФаТіЈ©ЗТios_by_readЈЁ¶БИЎI/OЈ©әЬёЯЈ¬ФтРиҫҜМиЎЈХвНЁіЈТвО¶ЧЕёГұнФЪЖө·ұРЮёДөДН¬КұУЦұ»Жө·ұ¶БИЎЈ¬ПЭИлЎ°ёХЛўРВөДКэҫЭВнЙПұ»ј·іц»әіеіШЎұөД¶сРФСӯ»·ЎЈ - ЧўТвЈәёГКУНјД¬ИПЦ»НіјЖInnoDBұнЎЈИз№ыПөНіЦР»№УРMyISAMұнЈ¬РиөҘ¶АІйСҜ
information_schema.TABLESАҙ»сИЎЖдDATA_LENGTHәНINDEX_LENGTHРЕПўЎЈ
pt-query-digest ҪвОцВэИХЦҫКұОӘКІГҙВ©өф Prepared Statement
pt-query-digest КЗ·ЦОцВэІйСҜИХЦҫөДЗҝҙу№ӨҫЯЈ¬ө«ФЪ·ЦОцК№УГPrepared StatementЈЁФӨҙҰАнУпҫдЈ©өДУҰУГКұЈ¬ҝЙДЬ»бЎ°¶ӘК§ЎұКэҫЭЎЈФӯТтФЪУЪMySQLөДВэІйСҜИХЦҫ»ъЦЖЈәЛьјЗВјөДКЗФӯКјSQLОДұҫЎЈ¶ФУЪТ»МхPrepared StatementЈ¬ИХЦҫ»бІр·ЦОӘ PrepareЈЁЧјұёЈ©әН ExecuteЈЁЦҙРРЈ©БҪМх¶АБўјЗВјЎЈpt-query-digest Д¬ИПНЁіЈЦ»ҫЫәП·ЦОц Execute Іҝ·ЦЈ¬ө«ОКМвФЪУЪЈ¬°у¶ЁІОКэәуөДКөјКЦҙРРјЖ»®ҝЙДЬУл Prepare ҪЧ¶ОЙъіЙөДјЖ»®НкИ«І»Н¬ЎЈ
ЗйҝцҝЙДЬёьёҙФУЈәИз№ыУҰУГіМРтК№УГ mysql_stmt_execute() ІўҝӘЖфБЛ query_cache_type=DEMANDЈ¬ВэІйСҜИХЦҫЙхЦБҝЙДЬНкИ«І»»бјЗВјёГУпҫдЈ¬өјЦВОЮҙУ·ЦОцЎЈ
- ФЪК№УГ
pt-query-digestЗ°Ј¬ҝЙПИУГmysqldumpslow -s tҝмЛЩЙЁГиИХЦҫЈ¬И·ИПКЗ·сҙжФЪҙуБҝPrepareәуёъЛжІ»Н¬ІОКэExecuteөДДЈКҪЎЈ - ҝЙТФіўКФФЛРР
pt-query-digest --filter '$event->{fingerprint} =~ m/^\s*execute/i' slow.logЈ¬ЗҝЦЖЦ»·ЦОцExecuteРРЈ¬ө«ХвИФОЮ·ЁҪвҫцІОКэ°у¶ЁҙшАҙөДјЖ»®ІоТмОКМвЎЈ - ¶ФУЪMySQL 8.0+УГ»§Ј¬ёьНЖјцөД·Ҫ·ЁКЗЦұҪУАыУГ
performance_schemaЎЈҝӘЖфperformance_schema.events_statements_history_longЈ¬И»әуНЁ№эsys.statement_analysisКУНјҪшРР·ЦОцЎЈЛьДЬ»№Фӯ°у¶ЁІОКэәуөДНкХыSQLЦёОЖЈ¬МṩёьЧјИ·өДРФДЬ»ӯПсЎЈ
ҝЙКУ»Ҝ·ЦОцКұЈ¬innodb_buffer_pool_pages_data Н»ҪөІ»өИУЪДЪҙжІ»Чг
ФЪҪшРРјаҝШёжҫҜ»тҝЙКУ»Ҝ·ЦОцКұЈ¬ҝҙөҪ innodb_buffer_pool_pages_dataЈЁ»әіеіШЦРҙжҙўКэҫЭөДТіКэЈ©ЦёұкН»И»ПВөшЈ¬әЬ¶аИЛөДөЪТ»·ҙУҰКЗЎ°ДЪҙжІ»ЧгЈ¬MySQLФЪ·иҝсЛўФаТіЎұЎЈө«КөјКЙПЈ¬ХвҝЙДЬЦёПтНкИ«І»Н¬өДЗйҝцЎЈ
ёьіЈјыөДФӯТтКЗЈәУРұнұ» DROP »т TRUNCATEЈ¬»тХЯBuffer PoolХэФЪФЪПЯөчХыҙуРЎЈЁНЁ№э SET GLOBAL innodb_buffer_pool_sizeЈ©ЎЈУИЖдФЪKubernetesөИИЭЖч»Ҝ»·ҫіЦРЈ¬Из№ыОӘPodЙиЦГөДДЪҙжПЮЦЖ№эУЪҪфХЕЈ¬Т»ө©ҙҘ·ўLinux OOM KillerЈ¬ХыёцmysqldҪшіМұ»ЙұЛАЦШЖфЈ¬pages_data ЧФИ»»б№йБгЎӘЎӘө«ХвҙҝҙвКЗҪшіМј¶ұрөДұААЈЈ¬УлBuffer PoolұҫЙнөДЕдЦГ»тС№БҰОЮ№ШЎЈ
- І»ТӘјұУЪПВҪбВЫЎЈПИјмІй
SHOW ENGINE INNODB STATUS\GКдіцЦРBUFFER POOL AND MEMORYІҝ·ЦЈ¬¶ФұИDatabase pagesәНFree buffersХвБҪёцЦөКЗ·сН¬ІҪПВҪөЎЈ - јмІй
information_schema.INNODB_METRICSұнЈ¬Ійҝҙbuffer_pool_resize_statusЦёұкКЗ·сОӘ1Ј¬ХвұнКҫBuffer PoolХэФЪөчХыҙуРЎЎЈ - ІйҝҙПөНіИХЦҫЈЁИз
/var/log/syslogЈ©Ј¬ЛСЛчЎ°out of memoryЎұ№ШјьЧЦЈ¬И·ИПКЗ·с·ўЙъБЛOOMЈ¬¶шІ»КЗҪц¶ўЧЕMySQLДЪІҝЦёұкІВІвЎЈ
ДЗГҙЈ¬КІГҙІЕКЗBuffer PoolГжБЩХжКөС№БҰөДРЕәЕДШЈҝ№ШјьФЪУЪБнНвБҪёцЦёұкЈәИз№ы innodb_buffer_pool_wait_freeЈЁөИҙэҝХПР»әіеТіөДҙОКэЈ©іЦРшФціӨЈ¬ЛөГчИ·КөУРПЯіМФЪөИҙэҝХПРТіЈ»Из№ы innodb_buffer_pool_read_ahead_evictedЈЁФӨ¶БТіёХјУФШҫНұ»ЗэЦрөДҙОКэЈ©Н»И»ҙу·щФцјУЈ¬ДЗёьКЗөдРНөД»әҙ涶¶ҜРЕәЕЈ¬ЛөГч»әіеіШҝЙДЬМ«РЎЈ¬»тХЯ№ӨЧчёәФШөД·ГОКДЈКҪ·ЗіЈЛж»ъЈ¬өјЦВФӨ¶Б»ъЦЖК§Р§ЎЈ
ПАУОП··ўІјҙЛОДҪцОӘБЛҙ«өЭРЕПўЈ¬І»ҙъұнПАУОП·НшХҫИПН¬Жд№Ыөг»тЦӨКөЖдГиКц
Па№Ш№ҘВФ
ёь¶аН¬АаёьРВ
ёь¶а




ИИУОНЖјц
ёь¶а-

- әҪМм»рјэДЈДвЖч
- Android/ | ДЈДвСшіЙ
- 2026-04-07
-

- ГьФЛЖпКҝНЕ
- Android/ | ҪЗЙ«°зСЭ
- 2026-03-30
-

-

-

-

-

- Ч№РЗҙуВҪ Вт¶П°ж
- Android/ | ҪЗЙ«°зСЭ
- 2026-03-30
-







- ПжICPұё14008430әЕ-1 П湫Нш°Іұё 43070302000280әЕ
- All Rights Reserved
- ұҫХҫОӘ·ЗУҜАыНшХҫЈ¬І»ҪУКЬИОәО№гёжЎЈұҫХҫЛщУРИнјюЈ¬¶јУЙНшУС
- ЙПҙ«Ј¬ИзУРЗЦ·ёДгөД°жИЁЈ¬Зл·ўУКјюёшxiayx666@163.com
- өЦЦЖІ»БјЙ«ЗйЎў·ҙ¶ҜЎўұ©БҰУОП·ЎЈЧўТвЧФОТұЈ»ӨЈ¬Ҫч·АКЬЖӯЙПөұЎЈ
- КК¶ИУОП·ТжДФЈ¬іБГФУОП·ЙЛЙнЎЈәПАн°ІЕЕКұјдЈ¬ПнКЬҪЎҝөЙъ»оЎЈ