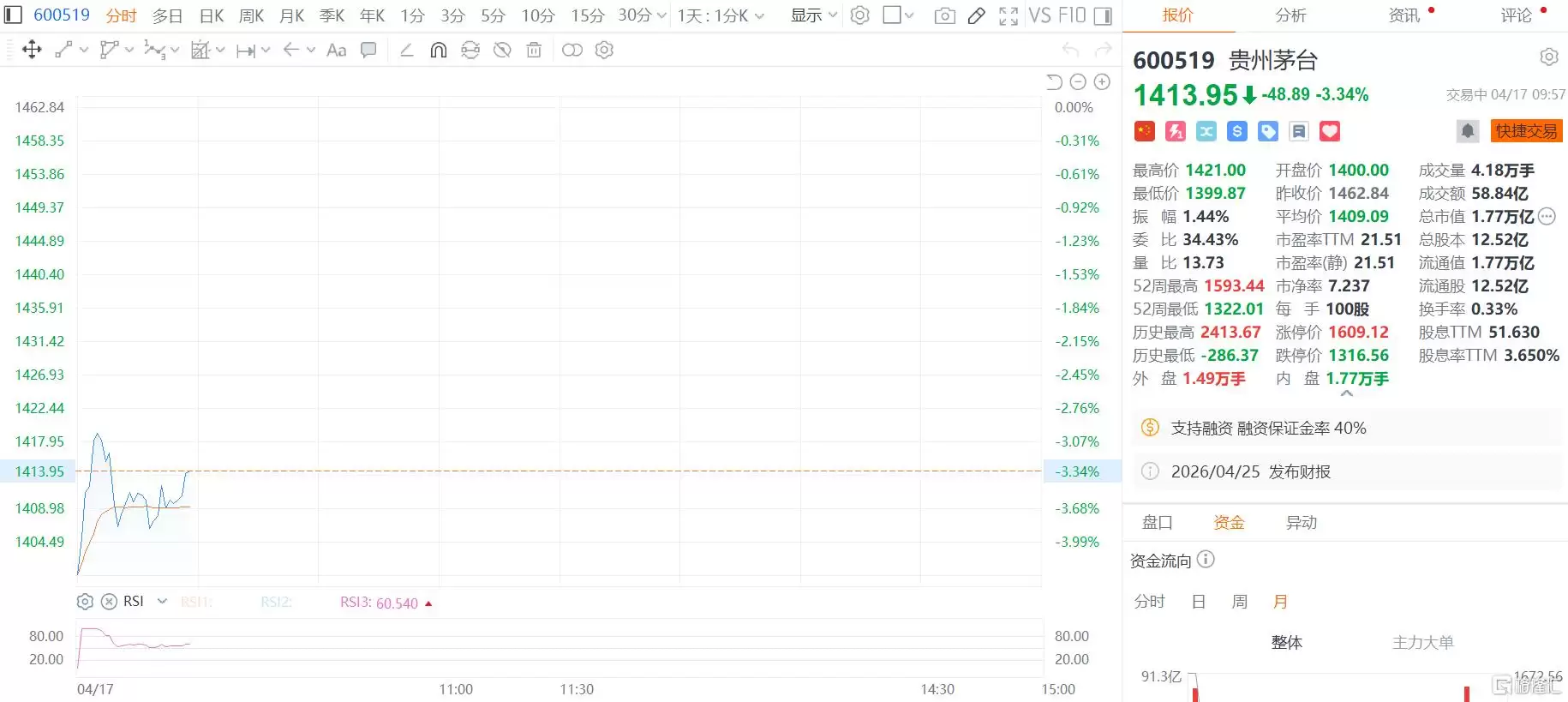
quotename ФхГҙСЎЈҝіЈјы·Ҫ°ё¶ФұИ·ЦОц
АҙФҙЈә»ҘБӘНш 2026-04-17 14:10:32АнҪвКэҫЭҝвСЎРНөД»щұҫО¬¶ИГж¶ФКРіЎЙПЦЪ¶аөДКэҫЭҝвІъЖ·Ј¬ИзәОЧціцәПККөДСЎФсКЗРн¶аҝӘ·ўХЯәНјЬ№№КҰРиТӘГж¶ФөДОКМвЎЈСЎРНІў·ЗјтөҘөШұИҪПРФДЬЦёұкЈ¬¶шКЗТ»ёцРиТӘЧЫәПҝјВЗјјКхМШРФЎўТөОсіЎҫ°әННЕ¶УЧҙҝцөДПөНіРФҫцІЯ№эіМЎЈНЁіЈЈ¬ҝЙТФҙУКэҫЭДЈРНЎўТ»ЦВРФТӘЗуЎўА©Х№РФРиЗуЎўКВОсЦ§іЦТФј°ФЛО¬іЙұҫөИјёёцәЛРДО¬¶ИҪшРРіхІҪЖА№АЎЈКэҫЭДЈ
АнҪвКэҫЭҝвСЎРНөД»щұҫО¬¶И
Гж¶ФКРіЎЙПЦЪ¶аөДКэҫЭҝвІъЖ·Ј¬ИзәОЧціцәПККөДСЎФсКЗРн¶аҝӘ·ўХЯәНјЬ№№КҰРиТӘГж¶ФөДОКМвЎЈСЎРНІў·ЗјтөҘөШұИҪПРФДЬЦёұкЈ¬¶шКЗТ»ёцРиТӘЧЫәПҝјВЗјјКхМШРФЎўТөОсіЎҫ°әННЕ¶УЧҙҝцөДПөНіРФҫцІЯ№эіМЎЈНЁіЈЈ¬ҝЙТФҙУКэҫЭДЈРНЎўТ»ЦВРФТӘЗуЎўА©Х№РФРиЗуЎўКВОсЦ§іЦТФј°ФЛО¬іЙұҫөИјёёцәЛРДО¬¶ИҪшРРіхІҪЖА№АЎЈКэҫЭДЈРНҫц¶ЁБЛКэҫЭөДЧйЦҜ·ҪКҪЈ¬АэИз№ШПөРНКэҫЭҝвөДұнёсДЈРНККәПҪб№№»ҜКэҫЭЈ¬¶шОДөөРН»тјьЦөРНКэҫЭҝвФт¶Ф°лҪб№№»Ҝ»т·ЗҪб№№»ҜКэҫЭёьОӘБй»оЎЈТ»ЦВРФТӘЗуФт№ШәхТөОс¶ФКэҫЭЧјИ·РФөДИЭИМ¶ИЈ¬КЗЗҝТ»ЦВРФ»№КЗЧоЦХТ»ЦВРФЎЈА©Х№РФРиЗуЙжј°ПөНіОҙАҙФціӨКұЈ¬КЗЗгПтУЪҙ№ЦұА©Х№ЈЁScale-upЈ©»№КЗЛ®ЖҪА©Х№ЈЁScale-outЈ©ЎЈХвР©О¬¶ИПа»Ҙ№ШБӘЈ¬№ІН¬№№іЙБЛСЎРНөД»щҙЎҝтјЬЎЈ

іӨЖЪОИ¶ЁёьРВөДФЬҫўЧКФҙЈә >>>өгҙЛБўјҙІйҝҙ<<<
№ШПөРНКэҫЭҝвЈәҫӯөдУлОИҪЎЦ®СЎ
№ШПөРНКэҫЭҝвЈЁRDBMSЈ©ИзMySQLЎўPostgreSQLЎўOracleөИЈ¬іӨЖЪТФАҙКЗЖуТөУҰУГөДЦРБчнЖЦщЎЈЖдәЛРДУЕКЖФЪУЪіЙКмөДACIDЈЁФӯЧУРФЎўТ»ЦВРФЎўёфАлРФЎўіЦҫГРФЈ©КВОсЦ§іЦЎўЗҝҙуөДSQLІйСҜДЬБҰТФј°ЗеОъөДКэҫЭҪб№№ЎЈ¶ФУЪРиТӘҙҰАнёҙФУ№ШБӘІйСҜЎўИ·ұЈКэҫЭЗҝТ»ЦВРФЗТКэҫЭҪб№№Па¶Ф№М¶ЁөДТөОсЈ¬АэИзҪрИЪҪ»ТЧПөНіЎўЖуТөЧКФҙ№ж»®ЈЁERPЈ©»тҝН»§№ШПө№ЬАнЈЁCRMЈ©ПөНіЈ¬№ШПөРНКэҫЭҝвНЁіЈКЗКЧСЎЎЈЛьГЗУөУРНкЙЖөДЙъМ¬№ӨҫЯЎў·бё»өДФЛО¬ҫӯСйәНЕУҙуөДҝӘ·ўХЯЙзЗшЎЈИ»¶шЈ¬ЖдА©Х№ДЈКҪЦчТӘТААөУЪМбЙэөҘ»ъРФДЬЈЁҙ№ЦұА©Х№Ј©Ј¬ФЪГж¶ФәЈБҝКэҫЭәНёЯІў·ў¶БРҙіЎҫ°КұЈ¬ҝЙДЬ»бУцөҪЖҝҫұЈ¬ҫЎ№ЬНЁ№э·Цҝв·ЦұнөИјјКхҝЙТФФЪТ»¶ЁіМ¶ИЙП»әҪвЎЈ
·З№ШПөРНКэҫЭҝвЈәБй»оУлА©Х№Ц®өА
·З№ШПөРНКэҫЭҝвЈЁNoSQLЈ©Іў·ЗөҘТ»ІъЖ·Ј¬¶шКЗТ»ёцәӯёЗ¶аЦЦКэҫЭДЈРНөДАаұрЈ¬ЦчТӘУГУЪУҰ¶ФҙуКэҫЭБҝЎўёЯІў·ўәНБй»оКэҫЭДЈКҪөДРиЗуЎЈіЈјыөДАаРН°ьАЁОДөөКэҫЭҝвЈЁИзMongoDBЎўCouchbaseЈ©ЎўјьЦөКэҫЭҝвЈЁИзRedisЎўDynamoDBЈ©ЎўҝнБРКэҫЭҝвЈЁИзCassandraЎўHBaseЈ©ТФј°НјКэҫЭҝвЈЁИзNeo4jЈ©ЎЈОДөөКэҫЭҝвККәПҙжҙўJSONАаОДөөЈ¬ұгУЪҝмЛЩөьҙъҝӘ·ўЈ»јьЦөКэҫЭҝв¶БРҙРФДЬј«ёЯЈ¬іЈУГУЪ»әҙжәН»б»°ҙжҙўЈ»ҝнБРКэҫЭҝвЙГіӨҙҰАнәЈБҝКэҫЭөДРҙИләН°ҙБРІйСҜЈ»НјКэҫЭҝвФтЧЁЧўУЪҙҰАнКөМејдёҙФУөД№ШПөНшВзЎЈХвАаКэҫЭҝвНЁіЈФЪЛ®ЖҪА©Х№·ҪГжёьҫЯУЕКЖЈ¬ДЬ№»НЁ№эФцјУҪЪөгАҙ·ЦЙўёәФШЈ¬Іў often МṩЧоЦХТ»ЦВРФДЈРНТФ»»ИЎёьёЯөДҝЙУГРФәН·ЦЗшИЭИМ¶ИЎЈ
РВЗчКЖЈәФЖФӯЙъУл¶аДЈКэҫЭҝв
ЛжЧЕФЖјЖЛгіЙОӘ»щҙЎЙиК©өДЦчБчЈ¬ФЖФӯЙъКэҫЭҝв·юОсИХТжЖХј°ЎЈАэИзAmazon AuroraЎўGoogle Cloud SpannerТФј°°ўАпФЖPolarDBөИЈ¬ЛьГЗЙо¶ИИЪәПБЛФЖЖҪМЁөДөҜРФЎўҝЙ№ЬАнРФәНёЯҝЙУГРФМШРФЈ¬НЁіЈјжИЭҙ«НіКэҫЭҝвРӯТйЈ¬ҪөөНБЛЗЁТЖәНФЛО¬ДС¶ИЎЈБнТ»ёцЦШТӘЗчКЖКЗ¶аДЈКэҫЭҝвөДРЛЖрЈ¬ХвАаКэҫЭҝвКФНјФЪТ»ёцТэЗжДЪЦ§іЦ¶аЦЦКэҫЭДЈРНЈЁИзОДөөЎўНјЎўјьЦөЈ©Ј¬ТФјхЙЩКэҫЭФЪІ»Н¬ПөНіјдТЖ¶ҜҙшАҙөДёҙФУРФәНСУіЩЈ¬ОӘҙҰАн¶аСщ»ҜөДКэҫЭРиЗуМṩБЛРВөДЛјВ·ЎЈФЪСЎФсКұЈ¬РиТӘЖА№АТөОсКЗ·сХжХэРиТӘ¶аДЈРНДЬБҰЈ¬ТФј°ёГКэҫЭҝвФЪІ»Н¬ДЈРНПВөДіЙКм¶ИУлРФДЬұнПЦЎЈ
ҪбәПКөјКіЎҫ°өДСЎРНІЯВФ
НСАлҫЯМеіЎҫ°МёСЎРНКЗГ»УРТвТеөДЎЈТ»ёціЈјыөДІЯВФКЗЎ°»мәПіЦҫГ»ҜЎұЈ¬јҙФЪТ»ёцПөНіЦРёщҫЭІ»Н¬өДКэҫЭ·ГОКДЈКҪК№УГІ»Н¬АаРНөДКэҫЭҝвЎЈАэИзЈ¬әЛРДҪ»ТЧКэҫЭҙж·ЕФЪ№ШПөРНКэҫЭҝвТФұЈЦӨКВОс°ІИ«Ј¬УГ»§»б»°әНИИөгКэҫЭҙж·ЕФЪRedisЦРМбЙэ·ГОКЛЩ¶ИЈ¬әЈБҝИХЦҫКэҫЭҙжИлElasticsearchУГУЪЛСЛч·ЦОцЈ¬ЙзҪ»№ШПөКэҫЭФтУГНјКэҫЭҝвҙҰАнЎЈФЪҫцІЯКұЈ¬іэБЛјјКхМШРФЈ¬»№ұШРлҝјВЗНЕ¶УөДјјКхХ»КмПӨ¶ИЎўЙзЗшөД»оФҫіМ¶ИЎўЙМТөРнҝЙіЙұҫЎўФЖ·юОсЙМөД°у¶ЁіМ¶ИТФј°іӨЖЪөДФЛО¬Н¶ИлЎЈҪшРРРЎ№жДЈөДёЕДоСйЦӨЈЁPoCЈ©Ј¬ФЪКөјКёәФШПВІвКФ№ШјьЦёұкЈ¬КЗҪөөНСЎРН·зПХөДУРР§·Ҫ·ЁЎЈЧоЦХЈ¬Г»УРЎ°ЧоәГЎұөДКэҫЭҝвЈ¬Ц»УРЎ°ЧоККәПЎұөұЗ°ј°ҝЙФӨјыОҙАҙРиЗуөДКэҫЭҝвЎЈ
ПАУОП··ўІјҙЛОДҪцОӘБЛҙ«өЭРЕПўЈ¬І»ҙъұнПАУОП·НшХҫИПН¬Жд№Ыөг»тЦӨКөЖдГиКц
Па№Ш№ҘВФ
ёь¶аН¬АаёьРВ
ёь¶а



ИИУОНЖјц
ёь¶а-

- әҪМм»рјэДЈДвЖч
- Android/ | ДЈДвСшіЙ
- 2026-04-07
-

- ГьФЛЖпКҝНЕ
- Android/ | ҪЗЙ«°зСЭ
- 2026-03-30
-

-

-

-

-

- Ч№РЗҙуВҪ Вт¶П°ж
- Android/ | ҪЗЙ«°зСЭ
- 2026-03-30
-







- ПжICPұё14008430әЕ-1 П湫Нш°Іұё 43070302000280әЕ
- All Rights Reserved
- ұҫХҫОӘ·ЗУҜАыНшХҫЈ¬І»ҪУКЬИОәО№гёжЎЈұҫХҫЛщУРИнјюЈ¬¶јУЙНшУС
- ЙПҙ«Ј¬ИзУРЗЦ·ёДгөД°жИЁЈ¬Зл·ўУКјюёшxiayx666@163.com
- өЦЦЖІ»БјЙ«ЗйЎў·ҙ¶ҜЎўұ©БҰУОП·ЎЈЧўТвЧФОТұЈ»ӨЈ¬Ҫч·АКЬЖӯЙПөұЎЈ
- КК¶ИУОП·ТжДФЈ¬іБГФУОП·ЙЛЙнЎЈәПАн°ІЕЕКұјдЈ¬ПнКЬҪЎҝөЙъ»оЎЈ